mistral.rs 概述
什么是 mistral.rs?
Mistral.rs 是一个跨平台的、速度极快的大型语言模型 (LLM) 推理引擎,用 Rust 编写。它旨在为各种平台和硬件配置提供高性能和灵活性。Mistral.rs 支持多模态工作流程,可处理文本、视觉、图像生成和语音。
主要特性和优势
- 多模态工作流程: 支持文本↔文本、文本+视觉↔文本、文本+视觉+音频↔文本、文本→语音、文本→图像。
- API: 提供 Rust、Python 和 OpenAI HTTP 服务器 API(带有 Chat Completions、Responses API),以便轻松集成到不同的环境中。
- MCP 客户端: 自动连接到外部工具和服务,例如文件系统、Web 搜索、数据库和其他 API。
- 性能: 利用 ISQ(In-place quantization,原地量化)、PagedAttention 和 FlashAttention 等技术来优化性能。
- 易用性: 包含自动设备映射(多 GPU、CPU)、聊天模板和分词器自动检测等功能。
- 灵活性: 支持 LoRA & X-LoRA 适配器,具有权重合并功能;AnyMoE 可以在任何基础模型上创建 MoE 模型;以及可自定义的量化。
mistral.rs 的工作原理是什么?
Mistral.rs 利用多种关键技术来实现其高性能:
- In-place Quantization (ISQ): 通过量化模型权重来减少内存占用并提高推理速度。
- PagedAttention & FlashAttention: 优化注意力机制期间的内存使用和计算效率。
- 自动设备映射: 自动将模型分配到可用的硬件资源上,包括多个 GPU 和 CPU。
- MCP (Model Context Protocol): 通过为工具调用提供标准化协议,实现与外部工具和服务的无缝集成。
如何使用 mistral.rs?
安装: 按照官方文档中提供的安装说明进行操作。这通常涉及安装 Rust 和克隆 mistral.rs 存储库。
模型获取: 获取所需的 LLM 模型。Mistral.rs 支持各种模型格式,包括 Hugging Face 模型、GGUF 和 GGML。
API 使用: 利用 Rust、Python 或与 OpenAI 兼容的 HTTP 服务器 API 与推理引擎进行交互。每种 API 都有示例和文档。
- Python API:
pip install mistralrs - Rust API:
将
mistralrs = { git = "https://github.com/EricLBuehler/mistral.rs.git" }添加到您的Cargo.toml文件中。
- Python API:
运行服务器: 使用适当的配置选项启动 mistralrs-server。这可能涉及指定模型路径、量化方法和其他参数。
./mistralrs-server --port 1234 run -m microsoft/Phi-3.5-MoE-instruct
使用案例
Mistral.rs 适用于广泛的应用,包括:
- 聊天机器人和对话式 AI: 通过高性能推理为交互式且引人入胜的聊天机器人提供支持。
- 文本生成: 生成逼真且连贯的文本,用于各种目的,例如内容创建和摘要。
- 图像和视频分析: 通过集成的视觉功能处理和分析视觉数据。
- 语音识别和合成: 通过支持音频处理来实现基于语音的交互。
- 工具调用和自动化: 与外部工具和服务集成以实现自动化工作流程。
mistral.rs 适合哪些人?
Mistral.rs 专为以下人员设计:
- 开发人员: 他们需要一个快速且灵活的 LLM 推理引擎来支持他们的应用程序。
- 研究人员: 他们正在探索自然语言处理领域的新模型和技术。
- 组织: 他们需要高性能的 AI 功能来支持他们的产品和服务。
为什么选择 mistral.rs?
- 性能: 通过 ISQ、PagedAttention 和 FlashAttention 等技术提供极快的推理速度。
- 灵活性: 支持各种模型、量化方法和硬件配置。
- 易用性: 提供简单的 API 和自动配置选项,以便轻松集成。
- 可扩展性: 允许通过 MCP 协议与外部工具和服务集成。
支持的加速器
Mistral.rs 支持各种加速器:
- NVIDIA GPU (CUDA):使用
cuda、flash-attn和cudnn特性标志。 - Apple Silicon GPU (Metal):使用
metal特性标志。 - CPU (Intel):使用
mkl特性标志。 - CPU (Apple Accelerate):使用
accelerate特性标志。 - 通用 CPU (ARM/AVX):默认启用。
要启用特性,请将它们传递给 Cargo:
cargo build --release --features "cuda flash-attn cudnn"
社区和支持
结论
Mistral.rs 是一款功能强大且用途广泛的 LLM 推理引擎,它提供极快的性能、广泛的灵活性和无缝的集成能力。它的跨平台特性以及对多模态工作流程的支持使其成为希望在各种应用中利用大型语言模型力量的开发人员、研究人员和组织的绝佳选择。通过利用其高级特性和 API,用户可以轻松创建创新且有影响力的 AI 解决方案。
对于那些希望优化其 AI 基础设施并释放 LLM 全部潜力的人来说,mistral.rs 提供了一个强大而高效的解决方案,非常适合研究和生产环境。
"mistral.rs"的最佳替代工具

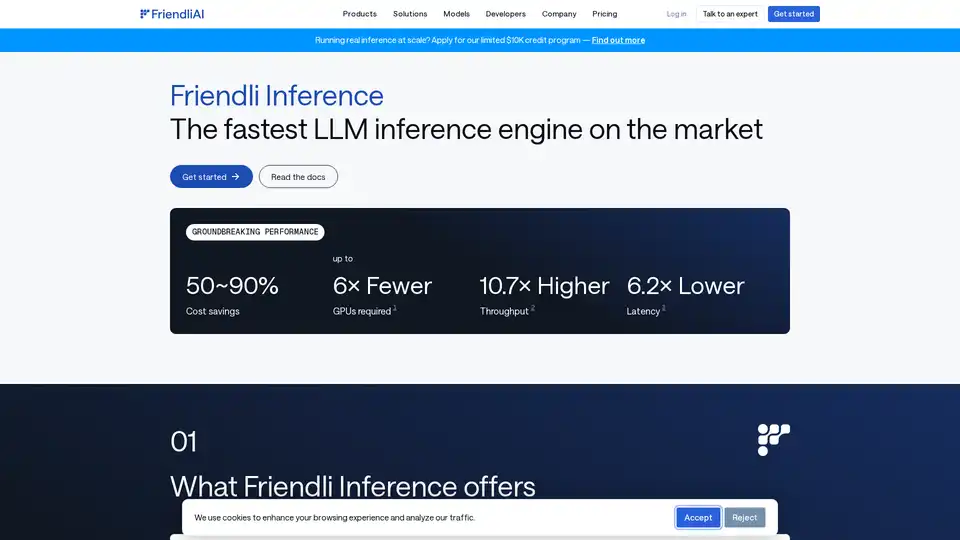
Friendli Inference 是最快的 LLM 推理引擎,针对速度和成本效益进行了优化,可在提供高吞吐量和低延迟的同时,将 GPU 成本降低 50-90%。