Friendli Inference 개요
Friendli Inference: 가장 빠른 LLM 추론 엔진
Friendli Inference란 무엇입니까?
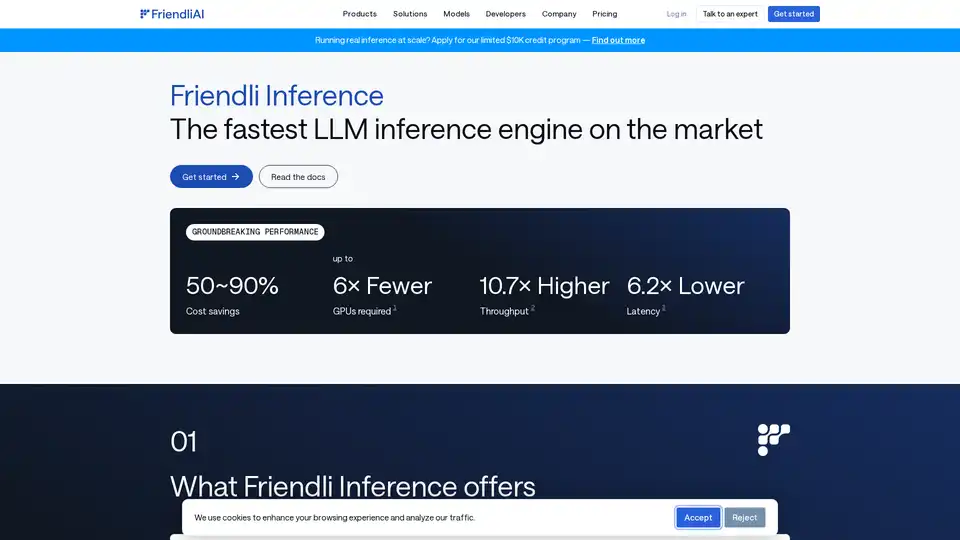
Friendli Inference는 대규모 언어 모델(LLM)의 서빙을 가속화하여 비용을 50~90%까지 크게 절감하도록 설계된 고도로 최적화된 엔진입니다. 성능 테스트에서 vLLM 및 TensorRT-LLM을 능가하는 시장에서 가장 빠른 LLM 추론 엔진으로 돋보입니다.
Friendli Inference는 어떻게 작동합니까?
Friendli Inference는 다음과 같은 몇 가지 핵심 기술을 통해 놀라운 성능을 달성합니다.
- 반복 일괄 처리(Iteration Batching): 이 혁신적인 일괄 처리 기술은 동시 생성 요청을 효율적으로 처리하여 기존 일괄 처리에 비해 LLM 추론 처리량을 최대 수십 배까지 높이는 동시에 동일한 대기 시간 요구 사항을 유지합니다. 미국, 한국, 중국에서 특허로 보호됩니다.
- DNN 라이브러리: Friendli DNN 라이브러리는 생성적 AI를 위해 특별히 설계된 최적화된 GPU 커널 세트로 구성됩니다. 이 라이브러리는 다양한 텐서 모양과 데이터 유형에 대해 더 빠른 LLM 추론을 가능하게 하고 양자화, MoE(Mixture of Experts) 및 LoRA 어댑터를 지원합니다.
- Friendli TCache: 이 지능형 캐싱 시스템은 자주 사용되는 계산 결과를 식별하고 저장하여 캐시된 결과를 활용하여 GPU의 작업 부하를 줄입니다.
- 추측 디코딩(Speculative Decoding): Friendli Inference는 추측 디코딩을 기본적으로 지원합니다. 이는 현재 토큰을 생성하는 동안 미래 토큰에 대한 교육된 추측을 병렬로 수행하여 LLM/LMM 추론 속도를 높이는 최적화 기술입니다. 이를 통해 추론 시간의 일부로 동일한 모델 출력을 보장합니다.
주요 기능 및 이점
- 상당한 비용 절감: LLM 서빙 비용을 50~90% 절감합니다.
- 다중 LoRA 서빙: 더 적은 GPU, 심지어 단일 GPU에서 여러 LoRA 모델을 동시에 지원합니다.
- 광범위한 모델 지원: 양자화된 모델 및 MoE를 포함한 광범위한 생성적 AI 모델을 지원합니다.
- 획기적인 성능:
- 최대 6배 적은 GPU가 필요합니다.
- 최대 10.7배 더 높은 처리량.
- 최대 6.2배 더 낮은 대기 시간.
주요 사항
- 단일 GPU에서 양자화된 Mixtral 8x7B 실행: Friendli Inference는 단일 NVIDIA A100 80GB GPU에서 양자화된 Mixtral-7x8B-instruct v0.1 모델을 실행할 수 있으며, 기준 vLLM 시스템에 비해 최소 4.1배 빠른 응답 시간과 3.8배 ~ 23.8배 더 높은 토큰 처리량을 달성합니다.
- 단일 GPU에서 양자화된 Llama 2 70B: 단일 A100 80 GB GPU에서 Llama 2 70B 4비트와 같은 AWQ-ed LLM을 원활하게 실행하여 정확도를 희생하지 않고 효율적인 LLM 배포와 뛰어난 효율성 향상을 가능하게 합니다.
- Friendli TCache로 더욱 빠른 TTFT: Friendli TCache는 반복 계산을 재사용하여 TTFT(Time to First Token)를 최적화하여 vLLM에 비해 11.3배에서 23배 더 빠른 TTFT를 제공합니다.
Friendli Inference 사용 방법
Friendli Inference는 생성적 AI 모델을 실행하는 세 가지 방법을 제공합니다.
- Friendli 전용 엔드포인트: 자동 조종 장치에서 생성적 AI 모델을 구축하고 실행합니다.
- Friendli 컨테이너: Friendli Inference를 사용하여 개인 환경에서 LLM 및 LMM 추론을 제공합니다.
- Friendli 서버리스 엔드포인트: 오픈 소스 생성적 AI 모델에 대한 빠르고 저렴한 API를 호출합니다.
Friendli Inference를 선택하는 이유
Friendli Inference는 LLM 추론 작업 부하의 성능과 비용 효율성을 최적화하려는 조직에 이상적인 솔루션입니다. 혁신적인 기술과 광범위한 기능을 통해 생성적 AI 모델을 배포하고 확장할 수 있는 강력한 도구입니다.
Friendli Inference는 누구를 위한 것입니까?
Friendli Inference는 다음에 적합합니다.
- 대규모 언어 모델을 배포하는 기업.
- 생성적 AI를 연구하는 연구원.
- AI 기반 애플리케이션을 구축하는 개발자.
LLM 추론을 최적화하는 가장 좋은 방법
LLM 추론을 최적화하는 가장 좋은 방법은 다른 솔루션에 비해 상당한 비용 절감, 높은 처리량 및 낮은 대기 시간을 제공하는 Friendli Inference를 사용하는 것입니다.
"Friendli Inference"의 최고의 대체 도구
Xander는 노코드 AI 모델 훈련을 가능하게 하는 오픈 소스 데스크톱 플랫폼입니다. 자연어로 작업을 설명하면 텍스트 분류, 이미지 분석, LLM 미세 조정에 대한 자동화된 파이프라인을 실행하며, 로컬 머신에서 프라이버시와 성능을 보장합니다。
개발자를 위한 번개처럼 빠른 AI 플랫폼. 간단한 API로 200개 이상의 최적화된 LLM과 멀티모달 모델 배포, 미세 조정 및 실행 - SiliconFlow.
mistral.rs는 Rust로 작성된 매우 빠른 LLM 추론 엔진으로, 멀티모달 워크플로우와 양자화를 지원합니다. Rust, Python 및 OpenAI 호환 HTTP 서버 API를 제공합니다.
vLLM은 최적화된 성능을 위해 PagedAttention 및 지속적인 일괄 처리를 특징으로 하는 LLM을 위한 고처리량 및 메모리 효율적인 추론 및 서비스 엔진입니다.