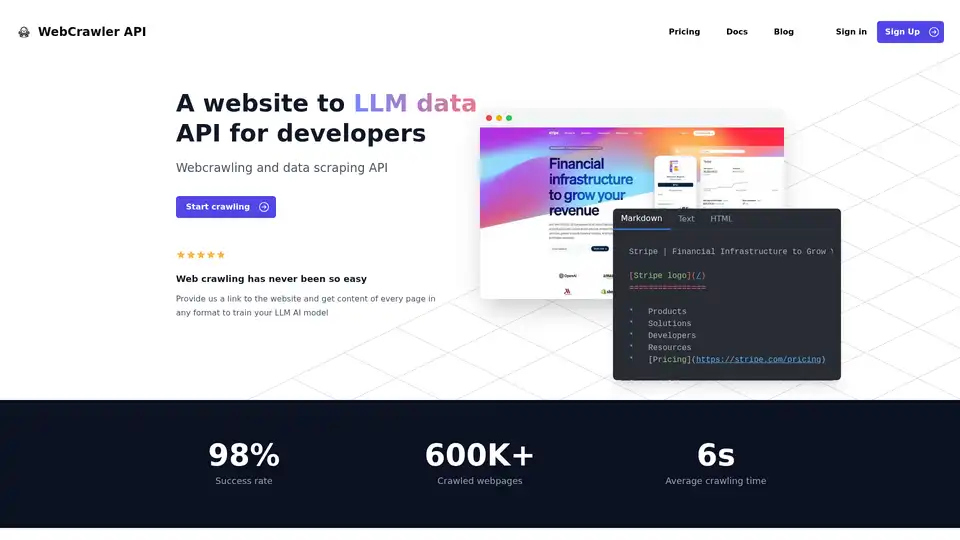
WebCrawler API 概述
WebCrawler API:轻松进行网络爬取和数据提取,助力 AI 发展
什么是 WebCrawler API?它是一款强大的工具,旨在简化从网站提取数据的过程,特别是为了训练大型语言模型 (LLM) 和其他 AI 应用程序。它能处理网络爬取的复杂性,让您专注于利用数据。
主要特性:
- 易于集成: 只需几行代码,即可使用 NodeJS、Python、PHP 或 .NET 集成 WebCrawlerAPI。
- 多样的输出格式: 以 Markdown、文本或 HTML 格式接收内容,根据您的需求量身定制。
- 高成功率: WebCrawlerAPI 拥有 98% 的成功率,可克服常见的爬取挑战,如反爬虫阻止、验证码和 IP 阻止。
- 全面的链接处理: 管理内部链接,删除重复项并清理 URL。
- JS 渲染: 以稳定的方式使用 Puppeteer 和 Playwright 来处理 JavaScript 繁重的网站。
- 可扩展的基础设施: 可靠地管理和存储数百万个已爬取的页面。
- 自动数据清理: 使用复杂的解析规则将 HTML 转换为纯文本或 Markdown。
- 代理管理: 包括无限代理使用,因此您无需担心 IP 限制。
WebCrawler API 的工作原理是什么?
WebCrawler API 抽象化了网络爬取的困难,例如:
- 链接处理: 管理内部链接,删除重复项并清理 URL。
- JS 渲染: 渲染 JavaScript 繁重的网站以提取动态内容。
- 反爬虫阻止: 绕过验证码、IP 阻止和速率限制。
- 存储: 管理和存储大量爬取的数据。
- 扩展: 在不同的服务器上处理多个爬虫。
- 数据清理: 将 HTML 转换为纯文本或 Markdown。
通过处理这些底层复杂性,WebCrawlerAPI 让您可以专注于真正重要的事情 – 利用提取的数据来开发您的 AI 项目。
如何使用 WebCrawler API?
- 注册 一个帐户并获取您的 API 访问密钥。
- 选择您首选的编程语言: NodeJS、Python、PHP 或 .NET。
- 将 WebCrawlerAPI 客户端 集成到您的代码中。
- 指定目标 URL 和所需的输出格式(Markdown、文本或 HTML)。
- 启动爬取 并检索提取的内容。
使用 NodeJS 的示例:
// npm i webcrawlerapi-js
import webcrawlerapi from "webcrawlerapi-js";
async function main() {
const client = new webcrawlerapi.WebcrawlerClient(
"YOUR API ACCESS KEY HERE",
)
const syncJob = await client.crawl({
"items_limit": 10,
"url": "https://stripe.com/",
"scrape_type": "markdown"
}
)
console.log(syncJob);
}
main().catch(console.error);
为什么选择 WebCrawler API?
- 专注于您的核心业务: 避免花费时间和资源来管理复杂的网络爬取基础设施。
- 访问干净且结构化的数据: 以您喜欢的格式接收数据,为 AI 训练做好准备。
- 扩展您的数据提取工作: 处理数百万个页面,而无需担心基础设施限制。
- 经济高效的定价: 只为成功的请求付费,没有订阅费。
WebCrawler API 适合哪些人?
WebCrawler API 非常适合:
- AI 和机器学习工程师: 他们需要大型数据集来训练他们的模型。
- 数据科学家: 他们需要从网站提取数据以进行分析和研究。
- 企业: 他们需要监控竞争对手、跟踪市场趋势或收集客户洞察。
定价
WebCrawlerAPI 提供简单的、基于使用量的定价,没有订阅费。您只需为成功的请求付费。可以使用成本计算器根据您计划爬取的页面数量来估算您的每月费用。
常见问题解答
- 什么是 WebcrawlerAPI? WebcrawlerAPI 是一个 API,可让您以高成功率从网站提取内容,处理代理、重试和无头浏览器。
- 我可以只爬取特定页面还是整个网站? 您可以指定在发出请求时是希望爬取特定页面还是整个网站。
- 我可以在 RAG 中使用爬取的数据或训练我自己的 AI 模型吗? 是的,爬取的数据可以在检索增强生成 (RAG) 系统中使用,也可以用来训练您自己的 AI 模型。
- 我需要支付订阅费用才能使用 WebcrawlerAPI 吗? 不,没有订阅费。您只需为成功的请求付费。
- 我可以在购买前试用 WebcrawlerAPI 吗? 请与他们联系以咨询试用选项。
- 如果我需要集成方面的帮助怎么办? 提供电子邮件支持。
使用 WebCrawlerAPI 提取网站数据以进行 AI 训练的最佳方式
WebCrawlerAPI 提供了一种简化的解决方案来提取网站数据,简化了网络爬取的复杂性,使您能够专注于 AI 模型训练和数据分析。凭借其高成功率、多功能的输出格式和高效的数据清理能力,它使 AI 工程师、数据科学家和企业能够有效地从网络收集有价值的见解。
相关文章
"WebCrawler API"的最佳替代工具
暂无图片
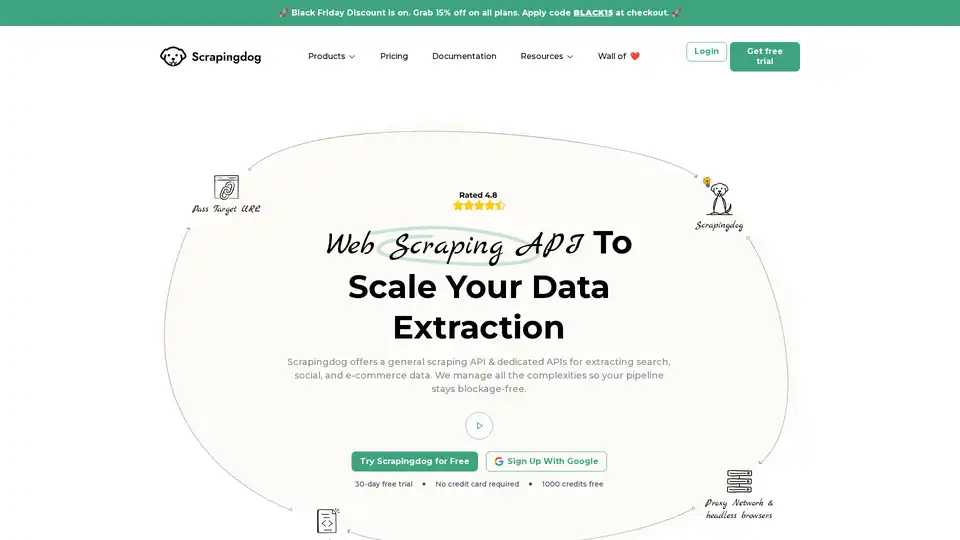
Scrapingdog 提供网页抓取 API 以及用于提取搜索、社交和电子商务数据的专用 API。它管理复杂性,通过真实浏览器渲染和旋转代理提供无阻塞数据。
网页抓取
数据提取
抓取 API
暂无图片
暂无图片
暂无图片
Firecrawl 是专为 AI 应用设计的领先网页爬取、抓取和搜索 API。它将网站转化为干净、结构化的 LLM 就绪数据,支持大规模 AI 代理使用可靠的网页提取,无需代理或复杂问题。
网页抓取API
AI网页爬取