Friendli Inference
Visão geral de Friendli Inference
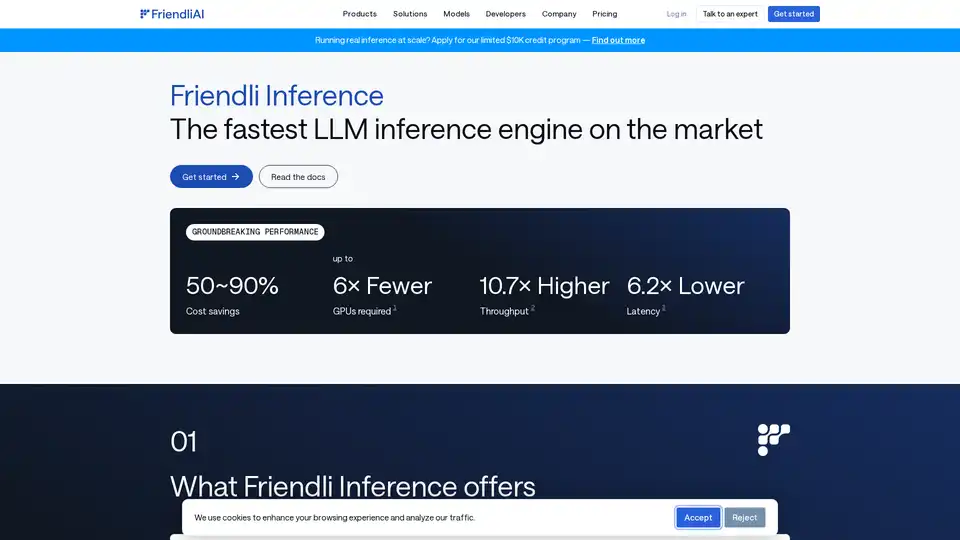
Friendli Inference: O Motor de Inferência LLM Mais Rápido
O que é Friendli Inference?
Friendli Inference é um motor altamente otimizado projetado para acelerar o fornecimento de Large Language Models (LLMs), reduzindo significativamente os custos em 50-90%. Destaca-se como o motor de inferência LLM mais rápido do mercado, superando vLLM e TensorRT-LLM em testes de desempenho.
Como funciona o Friendli Inference?
Friendli Inference alcança seu notável desempenho por meio de várias tecnologias-chave:
- Batching de Iteração: Esta tecnologia de batching inovadora lida eficientemente com solicitações de geração simultâneas, alcançando até dezenas de vezes maior taxa de transferência de inferência LLM em comparação com o batching convencional, mantendo os mesmos requisitos de latência. É protegido por patentes nos EUA, Coreia e China.
- Biblioteca DNN: Friendli DNN Library compreende um conjunto de kernels de GPU otimizados especificamente projetados para IA generativa. Esta biblioteca permite uma inferência LLM mais rápida para várias formas de tensores e tipos de dados, suporta quantização, Mixture of Experts (MoE) e adaptadores LoRA.
- Friendli TCache: Este sistema de cache inteligente identifica e armazena resultados computacionais frequentemente usados, reduzindo a carga de trabalho nas GPUs, aproveitando os resultados em cache.
- Decodificação Especulativa: Friendli Inference suporta nativamente a decodificação especulativa, uma técnica de otimização que acelera a inferência LLM/LMM, fazendo suposições educadas sobre tokens futuros em paralelo, enquanto gera o token atual. Isso garante saídas de modelo idênticas em uma fração do tempo de inferência.
Principais Características e Benefícios
- Economia de Custos Significativa: Reduza os custos de fornecimento de LLM em 50-90%.
- Fornecimento Multi-LoRA: Suporta simultaneamente vários modelos LoRA em menos GPUs, mesmo em uma única GPU.
- Amplo Suporte de Modelo: Suporta uma ampla gama de modelos de IA generativa, incluindo modelos quantizados e MoE.
- Desempenho Inovador:
- Até 6 vezes menos GPUs necessárias.
- Até 10,7 vezes maior taxa de transferência.
- Até 6,2 vezes menor latência.
Destaques
- Executando Mixtral 8x7B Quantizado em uma Única GPU: Friendli Inference pode executar um modelo Mixtral-7x8B-instruct v0.1 quantizado em uma única GPU NVIDIA A100 de 80 GB, alcançando pelo menos 4,1 vezes mais rápido o tempo de resposta e 3,8x ~ 23,8x maior taxa de transferência de tokens em comparação com um sistema vLLM de linha de base.
- Llama 2 70B Quantizado em GPU Única: Execute perfeitamente LLMs AWQ-ed, como Llama 2 70B de 4 bits, em uma única GPU A100 de 80 GB, permitindo uma implantação LLM eficiente e ganhos de eficiência notáveis sem sacrificar a precisão.
- TTFT Ainda Mais Rápido com Friendli TCache: Friendli TCache otimiza o Time to First Token (TTFT) reutilizando computações recorrentes, oferecendo TTFT de 11,3x a 23x mais rápido em comparação com vLLM.
Como Usar o Friendli Inference
Friendli Inference oferece três maneiras de executar modelos de IA generativa:
- Friendli Dedicated Endpoints: Crie e execute modelos de IA generativa no piloto automático.
- Friendli Container: Sirva inferências LLM e LMM com Friendli Inference em seu ambiente privado.
- Friendli Serverless Endpoints: Chame a API rápida e acessível para modelos de IA generativa de código aberto.
Por que escolher Friendli Inference?
Friendli Inference é a solução ideal para organizações que buscam otimizar o desempenho e a relação custo-benefício de suas cargas de trabalho de inferência LLM. Suas tecnologias inovadoras e ampla gama de recursos o tornam uma ferramenta poderosa para implantar e escalar modelos de IA generativa.
Para quem é o Friendli Inference?
Friendli Inference é adequado para:
- Empresas que implantam grandes modelos de linguagem.
- Pesquisadores que trabalham com IA generativa.
- Desenvolvedores que criam aplicativos com tecnologia de IA.
Melhor maneira de otimizar a inferência LLM?
A melhor maneira de otimizar a inferência LLM é usar Friendli Inference, que oferece economia de custos significativa, alta taxa de transferência e baixa latência em comparação com outras soluções.
Assistente de Programação com IA Complementação Automática de Código Revisão e Otimização de Código com IA Desenvolvimento Low-Code e No-Code com IA
Melhores ferramentas alternativas para "Friendli Inference"
vLLM é um mecanismo de inferência e serviço de alto rendimento e com eficiência de memória para LLMs, apresentando PagedAttention e processamento em lote contínuo para desempenho otimizado.
mistral.rs é um motor de inferência LLM incrivelmente rápido escrito em Rust, com suporte a fluxos de trabalho multimodais e quantização. Oferece APIs Rust, Python e servidor HTTP compatível com OpenAI.
LM Studio é um aplicativo de desktop fácil de usar para executar e baixar modelos de linguagem grandes (LLMs) de código aberto como LLaMa e Gemma localmente no seu computador. Ele apresenta uma UI de chat no aplicativo e um servidor compatível com OpenAI para interação offline, tornando a IA acessível sem habilidades de programação.
KoboldCpp: Execute modelos GGUF facilmente para geração de texto e imagem com IA usando uma interface KoboldAI. Arquivo único, instalação zero. Suporta CPU/GPU, STT, TTS e Stable Diffusion.