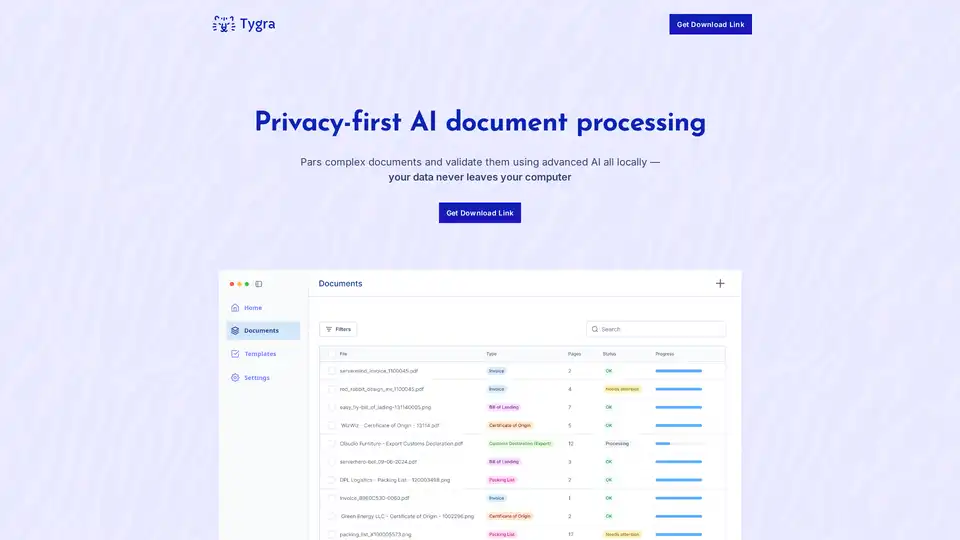
Tygra 개요
Tygra: 개인 정보 보호 우선 AI 문서 처리
Tygra는 개인 정보 보호에 중점을 둔 AI 문서 처리를 위해 설계된 데스크톱 애플리케이션입니다. 사용자는 복잡한 문서를 로컬에서 구문 분석하고 유효성을 검사하여 민감한 데이터가 컴퓨터에서 유출되지 않도록 할 수 있습니다. 따라서 엄격한 개인 정보 보호 및 규정 준수 요구 사항이 있는 조직에 이상적입니다.
Tygra란 무엇입니까?
Tygra는 문서 처리를 자동화하는 AI 기반 도구입니다. PDF, JPG 및 PNG 형식을 지원하며 고급 AI 모델을 사용하여 데이터를 추출하고 비즈니스 규칙 및 규정에 따라 정보를 검증합니다. Tygra의 핵심 기능은 인터넷 연결 없이 장치에서 완전히 작동할 수 있다는 점이며, 이는 완전한 개인 정보를 보장합니다.
Tygra는 어떻게 작동합니까?
Tygra는 OCR 및 머신 러닝을 포함한 고급 AI를 활용하여 문서의 컨텍스트, 구조 및 의미를 이해합니다. 텍스트만 인식하는 기존 OCR과 달리 Tygra는 문서 레이아웃을 이해하고 복잡한 데이터 관계를 추출하며 정보를 검증합니다. 따라서 특히 복잡하고 전문화된 문서의 경우 정확도와 신뢰성이 훨씬 향상됩니다.
주요 기능 및 이점:
- 개인 정보 보호 우선 접근 방식: 모든 데이터 처리는 컴퓨터에서 로컬로 이루어지므로 민감한 정보가 장치 또는 네트워크에서 유출되지 않습니다.
- 높은 정확도: Tygra는 컨텍스트와 구조를 이해하는 고급 AI 모델을 사용하여 기존 OCR보다 훨씬 뛰어난 성능을 제공합니다.
- 신뢰할 수 있는 데이터 추출: 구조화되지 않은 문서에서 데이터를 정확하게 추출하여 사용 가능한 정보로 변환합니다.
- 오프라인 기능: 인터넷 연결이 필요하지 않으므로 완전한 개인 정보 보호 및 보안이 보장됩니다.
- 다양한 파일 형식 지원: Tygra는 PDF, JPG 및 PNG 파일 형식을 지원합니다.
사용 사례:
Tygra는 정확성과 개인 정보 보호가 중요한 다양한 산업에 적합합니다.
- 금융: 사기 탐지, KYC(고객 알기), 대출 및 모기지 신청서, 은행 명세서 및 송장.
- 물류: 배송 영수증, 운임 견적, 구매 주문, 통관 신고서 및 선하 증권.
- 보험: 위험 평가, 보험 정책 관리, 갱신 통지 및 보험 청구 양식.
- 의료: 전자 건강 기록(EHR), 의료 청구, 실험실 보고서 및 처방전 양식.
- 법률: 계약 분석, 법적 소송 및 임상 노트.
- 교육: 학생 등록 양식, 성적 증명서, 과제 제출 및 장학금 신청.
Tygra를 선택하는 이유?
조직은 최고 수준의 개인 정보 보호 및 보안을 유지하면서 정확하고 신뢰할 수 있는 데이터 추출을 제공하는 Tygra의 능력을 높이 평가합니다. 클라우드 기반 솔루션과 달리 Tygra는 민감한 정보가 완전히 사용자의 제어 하에 있도록 보장합니다.
Tygra는 누구를 위한 것입니까?
Tygra는 다음과 같은 경우에 이상적입니다.
- 엄격한 개인 정보 보호 및 규정 준수 요구 사항을 준수하면서 민감한 문서를 처리해야 하는 조직.
- 기존 OCR 소프트웨어보다 정확하고 신뢰할 수 있는 대안을 찾는 기업.
- 데이터 개인 정보 보호가 가장 중요한 금융, 의료 및 법률과 같은 산업.
가격:
Tygra는 페이지 수를 기준으로 계층화된 가격 계획을 제공합니다.
- 표준: 10,000페이지당 월 $300
- 프로: 30,000페이지당 월 $600
- 엔터프라이즈: 사용자 정의 볼륨에 대한 사용자 정의 가격
최소 장치 요구 사항:
Tygra를 효과적으로 실행하려면 M3 또는 M4 칩, 24GB RAM 이상, 약 50GB의 사용 가능한 디스크 공간이 있는 장치를 사용하는 것이 좋습니다.
Tygra는 사용자 데이터를 수집합니까?
Tygra는 파일의 콘텐츠를 수집, 저장 또는 처리하지 않습니다. 모든 데이터는 장치에 완전히 남아 있습니다. 이 애플리케이션은 익명의 사용 분석 및 충돌 진단을 수집합니다(사용자는 옵트아웃할 수 있음).
Tygra 사용 방법
- Tygra 데스크톱 애플리케이션을 다운로드하여 설치합니다.
- 처리할 문서(PDF, JPG 또는 PNG)를 가져옵니다.
- Tygra의 AI가 문서를 로컬에서 자동으로 구문 분석하고 유효성을 검사합니다.
- 추출된 데이터를 검토하고 정확성을 확인합니다.
- 처리된 데이터를 구조화된 형식으로 내보내 추가 분석하거나 시스템에 통합합니다.
Tygra를 선택함으로써 현대 기업은 문서를 정확하고 안전하게 처리하여 데이터 보안 및 개인 정보 보호 규정 준수를 보장할 수 있습니다.
"Tygra"의 최고의 대체 도구
Unstract는 LLM을 사용하여 비정형 문서에서 데이터를 추출하기 위해 특별히 구축된 오픈 소스 노코드 플랫폼으로, 높은 정확도를 제공합니다. 비정형 데이터에 대한 API 및 ETL 파이프라인을 쉽게 배포할 수 있습니다.
Parseflow: AI 기반 파싱은 99% 정확도와 PII 보호를 통해 송장, 영수증, 계약서, 이미지에서 데이터를 추출합니다.

elDoc은 전자 서명, 워크플로 자동화, 보안 파일 관리 및 AI 문서 처리를 제공하는 AI 기반 문서 우수성 플랫폼입니다. 오늘 무료 평가판을 시작하십시오!

Kadoa는 코드 없이 대규모 데이터 추출을 자동화하는 AI 기반 웹 스크래핑 도구입니다. 실시간 모니터링, AI 에이전트 스크래핑 및 엔터프라이즈급 보안과 같은 기능을 제공합니다.