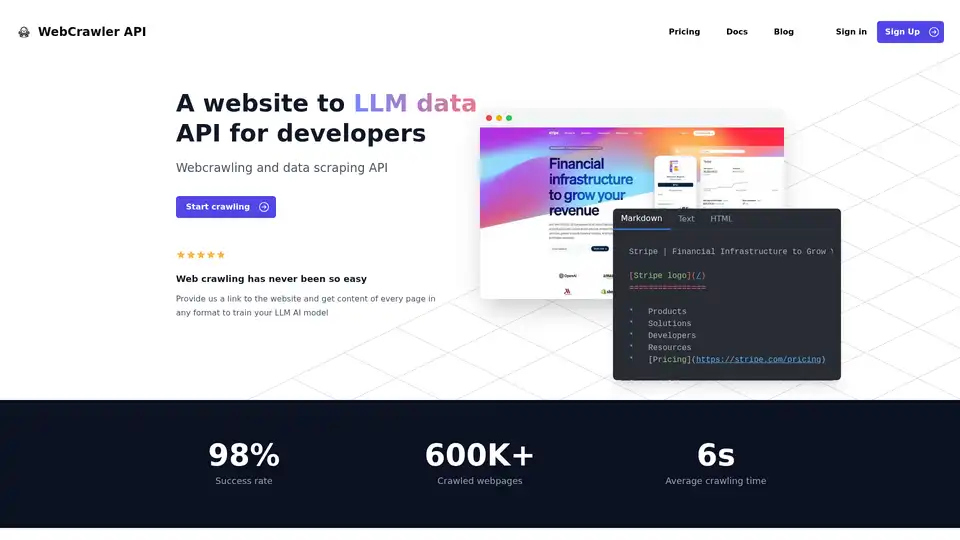
WebCrawler API の概要
WebCrawler API: AIのための容易なWebクロールとデータ抽出
WebCrawler APIとは? 大規模言語モデル(LLM)やその他のAIアプリケーションをトレーニングするために、ウェブサイトからデータを抽出するプロセスを簡素化する強力なツールです。Webクローリングの複雑さを処理し、データの利用に集中できるようにします。
主な機能:
- 簡単な統合: NodeJS、Python、PHP、または.NETを使用して、わずか数行のコードでWebCrawlerAPIを統合します。
- 多様な出力形式: ニーズに合わせて、Markdown、テキスト、またはHTML形式でコンテンツを受信します。
- 高い成功率: WebCrawlerAPIは98%の成功率を誇り、アンチボットブロック、CAPTCHA、IPブロックなどの一般的なクロール課題を克服します。
- 包括的なリンク処理: 内部リンクの管理、重複の削除、URLのクリーニングを行います。
- JSレンダリング: JavaScriptを多用するウェブサイトを処理するために、PuppeteerとPlaywrightを安定した方法で使用します。
- スケーラブルなインフラストラクチャ: 数百万のクロールされたページを確実に管理および保存します。
- 自動データクリーニング: 複雑な解析ルールを使用してHTMLをクリーンなテキストまたはMarkdownに変換します。
- プロキシ管理: 無制限のプロキシ使用が含まれているため、IP制限を気にする必要はありません。
WebCrawler APIはどのように機能しますか?
WebCrawler APIは、次のようなWebクローリングの困難さを抽象化します。
- リンク処理: 内部リンクの管理、重複の削除、URLのクリーニング。
- JSレンダリング: JavaScriptを多用するウェブサイトをレンダリングして、動的なコンテンツを抽出します。
- アンチボットブロック: CAPTCHA、IPブロック、およびレート制限をバイパスします。
- ストレージ: 大量のクロールされたデータの管理と保存。
- スケーリング: 異なるサーバー間で複数のクローラーを処理します。
- データクリーニング: HTMLをクリーンなテキストまたはMarkdownに変換します。
WebCrawlerAPIは、これらの基盤となる複雑さを処理することにより、抽出されたデータをAIプロジェクトに活用するという本当に重要なことに集中できるようにします。
WebCrawler APIの使用方法
- アカウントにサインアップし、APIアクセスキーを取得します。
- 希望するプログラミング言語を選択してください: NodeJS、Python、PHP、または.NET。
- WebCrawlerAPIクライアントをコードに統合します。
- ターゲットURLと必要な出力形式(Markdown、テキスト、またはHTML)を指定します。
- クロールを開始し、抽出されたコンテンツを取得します。
NodeJSを使用した例:
// npm i webcrawlerapi-js
import webcrawlerapi from "webcrawlerapi-js";
async function main() {
const client = new webcrawlerapi.WebcrawlerClient(
"YOUR API ACCESS KEY HERE",
)
const syncJob = await client.crawl({
"items_limit": 10,
"url": "https://stripe.com/",
"scrape_type": "markdown"
}
)
console.log(syncJob);
}
main().catch(console.error);
WebCrawler APIを選択する理由
- コアビジネスに集中する: 複雑なWebクローリングインフラストラクチャの管理に時間とリソースを費やすことを避けます。
- クリーンで構造化されたデータにアクセスする: AIトレーニングの準備ができた、好みの形式でデータを受信します。
- データ抽出の取り組みを拡大する: インフラストラクチャの制限を気にせずに、数百万のページを処理します。
- 費用対効果の高い価格設定: 成功したリクエストに対してのみ支払い、サブスクリプション料金はありません。
WebCrawler APIは誰のためのものですか?
WebCrawler APIは以下に最適です。
- AIおよび機械学習エンジニア: モデルをトレーニングするために大規模なデータセットが必要です。
- データサイエンティスト: 分析と研究のためにウェブサイトからデータを抽出する必要があります。
- 企業: 競合他社を監視し、市場の動向を追跡し、顧客の洞察を収集する必要があります。
価格
WebCrawlerAPIは、サブスクリプション料金なしで、シンプルな従量制の価格設定を提供します。成功したリクエストに対してのみ支払います。クロールする予定のページ数に基づいて月額費用を見積もるためのコスト計算ツールが利用可能です。
FAQ
- WebcrawlerAPIとは何ですか? WebcrawlerAPIは、プロキシ、再試行、およびヘッドレスブラウザーを処理して、高い成功率でウェブサイトからコンテンツを抽出できるAPIです。
- 特定のページまたはウェブサイト全体のみをクロールできますか? リクエストを行うときに、特定のページまたはウェブサイト全体をクロールするかどうかを指定できます。
- クロールされたデータをRAGで使用したり、独自のAIモデルをトレーニングしたりできますか? はい、クロールされたデータは、検索拡張生成(RAG)システムで使用したり、独自のAIモデルをトレーニングするために使用したりできます。
- WebcrawlerAPIを使用するにはサブスクリプションを支払う必要がありますか? いいえ、サブスクリプション料金はありません。成功したリクエストに対してのみ支払います。
- 購入前にWebcrawlerAPIを試してみることはできますか? 試用オプションについて問い合わせるには、彼らに連絡してください。
- 統合についてサポートが必要な場合はどうすればよいですか? メールサポートが提供されています。
WebCrawlerAPIを使用したAIトレーニングのためのウェブサイトデータを抽出する最良の方法
WebCrawlerAPIは、ウェブサイトデータを抽出するための合理化されたソリューションを提供し、Webクローリングの複雑さを簡素化し、AIモデルのトレーニングとデータ分析に集中できるようにします。その高い成功率、多様な出力形式、および効率的なデータクリーニング機能により、AIエンジニア、データサイエンティスト、および企業はウェブから貴重な洞察を効果的に収集できます。
"WebCrawler API" のベストな代替ツール
Firecrawl は、AI アプリケーション向けに設計された领先のウェブクローリング、スクラッピング、検索 API です。ウェブサイトをクリーンで構造化された LLM 対応データに変換し、スケールで AI エージェントをプロキシなしで信頼性の高いウェブ抽出で強化します。

Olostep は、AI および研究エージェント向けのウェブデータ API です。リアルタイムで任意のウェブサイトから構造化されたウェブデータを抽出し、ウェブ調査ワークフローを自動化できます。ユースケースには、AI 用のデータ、スプレッドシートの充実、リードの生成などが含まれます。
Exaは、開発者向けに設計されたAI搭載の検索エンジンとウェブデータAPIです。高速なウェブ検索、複雑なクエリのためのウェブセット、およびクローリング、回答、詳細な研究のためのツールを提供し、AIがリアルタイムの情報にアクセスできるようにします。