WebCrawler API
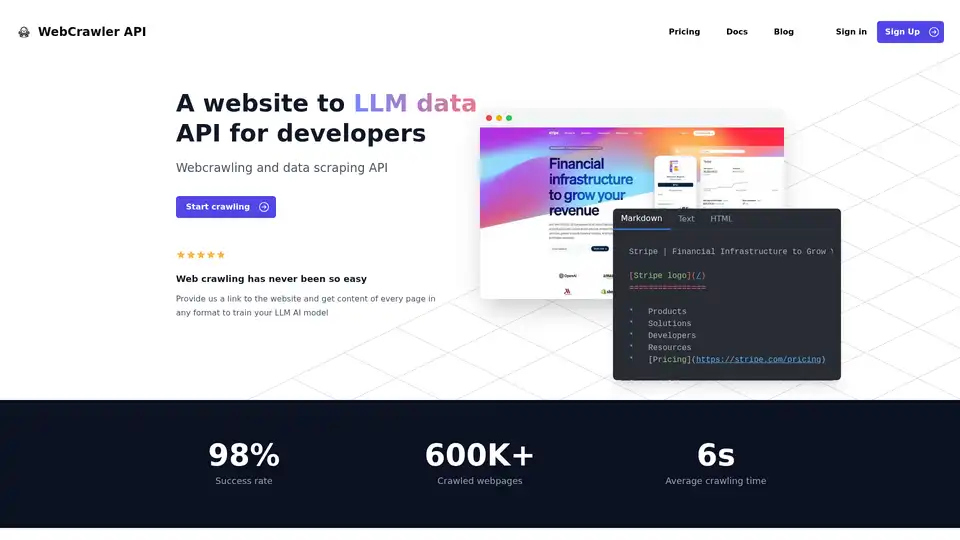
Vue d'ensemble de WebCrawler API
API WebCrawler : Exploration Web et Extraction de Données Simplifiées pour l'IA
Qu'est-ce que l'API WebCrawler ? C'est un outil puissant conçu pour simplifier le processus d'extraction de données depuis des sites web, spécifiquement pour l'entraînement de Grands Modèles de Langue (LLM) et d'autres applications d'IA. Il gère les complexités de l'exploration web, vous permettant de vous concentrer sur l'utilisation des données.
Fonctionnalités Clés :
- Intégration Facile: Intégrez WebCrawlerAPI avec seulement quelques lignes de code en utilisant NodeJS, Python, PHP, ou .NET.
- Formats de Sortie Polyvalents: Recevez le contenu aux formats Markdown, Texte ou HTML, adaptés à vos besoins.
- Taux de Succès Élevé: Avec un taux de succès de 98%, WebCrawlerAPI surmonte les défis courants de l'exploration web comme les blocages anti-bots, les CAPTCHAs, et les blocages d'IP.
- Gestion Complète des Liens: Gère les liens internes, supprime les doublons, et nettoie les URLs.
- Rendu JS: Emploie Puppeteer et Playwright de manière stable pour gérer les sites web riches en JavaScript.
- Infrastructure Évolutive: Gère et stocke de manière fiable des millions de pages explorées.
- Nettoyage Automatique des Données: Convertit le HTML en texte clair ou en Markdown en utilisant des règles d'analyse complexes.
- Gestion des Proxies: Inclut l'utilisation illimitée de proxies, vous n'avez donc pas à vous soucier des restrictions d'IP.
Comment fonctionne l'API WebCrawler ?
L'API WebCrawler simplifie les difficultés de l'exploration web, telles que :
- Gestion des Liens: Gestion des liens internes, suppression des doublons, et nettoyage des URLs.
- Rendu JS: Rendu des sites web riches en JavaScript pour extraire le contenu dynamique.
- Blocages Anti-Bots: Contournement des CAPTCHAs, des blocages d'IP, et des limitations de débit.
- Stockage: Gestion et stockage de grands volumes de données explorées.
- Évolutivité: Gestion de multiples crawlers à travers différents serveurs.
- Nettoyage des Données: Conversion du HTML en texte clair ou en Markdown.
En gérant ces complexités sous-jacentes, WebCrawlerAPI vous permet de vous concentrer sur ce qui compte vraiment : l'utilisation des données extraites pour vos projets d'IA.
Comment utiliser l'API WebCrawler ?
- Inscrivez-vous pour obtenir un compte et obtenir votre clé d'accès API.
- Choisissez votre langage de programmation préféré: NodeJS, Python, PHP, ou .NET.
- Intégrez le client WebCrawlerAPI dans votre code.
- Spécifiez l'URL cible et le format de sortie souhaité (Markdown, Texte, ou HTML).
- Lancez l'exploration et récupérez le contenu extrait.
Exemple en utilisant NodeJS :
// npm i webcrawlerapi-js
import webcrawlerapi from "webcrawlerapi-js";
async function main() {
const client = new webcrawlerapi.WebcrawlerClient(
"YOUR API ACCESS KEY HERE",
)
const syncJob = await client.crawl({
"items_limit": 10,
"url": "https://stripe.com/",
"scrape_type": "markdown"
}
)
console.log(syncJob);
}
main().catch(console.error);
Pourquoi choisir l'API WebCrawler ?
- Concentrez-vous sur votre cœur de métier: Évitez de dépenser du temps et des ressources pour gérer une infrastructure complexe d'exploration web.
- Accédez à des données propres et structurées: Recevez les données dans votre format préféré, prêtes pour l'entraînement de l'IA.
- Faites évoluer vos efforts d'extraction de données: Gérez des millions de pages sans vous soucier des limitations d'infrastructure.
- Tarification rentable: Payez uniquement pour les requêtes réussies, sans frais d'abonnement.
À qui s'adresse l'API WebCrawler ?
L'API WebCrawler est idéale pour :
- Les ingénieurs en IA et en apprentissage automatique: Qui ont besoin de grands ensembles de données pour entraîner leurs modèles.
- Les scientifiques des données: Qui ont besoin d'extraire des données de sites web pour l'analyse et la recherche.
- Les entreprises: Qui ont besoin de surveiller les concurrents, de suivre les tendances du marché ou de recueillir des informations sur les clients.
Tarification
WebCrawlerAPI offre une tarification simple, basée sur l'utilisation, sans frais d'abonnement. Vous ne payez que pour les requêtes réussies. Un calculateur de coûts est disponible pour estimer vos dépenses mensuelles en fonction du nombre de pages que vous prévoyez d'explorer.
FAQ
- Qu'est-ce que WebcrawlerAPI ? WebcrawlerAPI est une API qui vous permet d'extraire du contenu de sites web avec un taux de succès élevé, en gérant les proxies, les tentatives et les navigateurs sans tête.
- Puis-je uniquement explorer des pages spécifiques ou l'ensemble du site web ? Vous pouvez spécifier si vous souhaitez explorer des pages spécifiques ou l'ensemble du site web lors de la formulation d'une requête.
- Puis-je utiliser les données explorées dans RAG ou entraîner mon propre modèle d'IA ? Oui, les données explorées peuvent être utilisées dans les systèmes de génération augmentée par récupération (RAG) ou pour entraîner vos propres modèles d'IA.
- Dois-je payer un abonnement pour utiliser WebcrawlerAPI ? Non, il n'y a pas de frais d'abonnement. Vous ne payez que pour les requêtes réussies.
- Puis-je essayer WebcrawlerAPI avant d'acheter ? Contactez-les pour vous renseigner sur les options d'essai.
- Que faire si j'ai besoin d'aide pour l'intégration ? Un support par e-mail est fourni.
Meilleure façon d'extraire des données de sites web pour l'entraînement à l'IA avec WebCrawlerAPI
WebCrawlerAPI fournit une solution rationalisée pour extraire des données de sites web, simplifiant les complexités de l'exploration web et vous permettant de vous concentrer sur l'entraînement des modèles d'IA et l'analyse des données. Avec son taux de succès élevé, ses formats de sortie polyvalents et ses capacités de nettoyage des données efficaces, il permet aux ingénieurs en IA, aux scientifiques des données et aux entreprises de recueillir efficacement des informations précieuses sur le web.
Gestion des Tâches et Projets par IA Résumé de Document et Lecture par IA Recherche Intelligente par IA Analyse de Données par IA Flux de Travail Automatisé
Meilleurs outils alternatifs à "WebCrawler API"
Firecrawl est l'API de crawling, scraping et recherche web leader conçue pour les applications IA. Elle transforme les sites web en données propres, structurées et prêtes pour LLM à grande échelle, alimentant les agents IA avec une extraction web fiable sans proxies ni tracas.
Skrape.ai est un outil d'extraction web par IA qui extrait des données structurées et propres des sites web. Idéal pour les systèmes RAG, l'entraînement de l'IA et l'analyse de données.
UseScraper est une API de web scraping et de crawling ultra-rapide. Scrapez n'importe quelle URL instantanément, crawlez des sites web entiers et sortez des données en texte brut, HTML ou Markdown. Les 1 000 premières pages sont gratuites.
Schemawriter.ai est un générateur de balisage schema alimenté par IA qui automatise les données structurées JSON-LD pour les pages web. Il extrait les entités des concurrents, génère des schemas géorayon et entreprise locale, et optimise le contenu avec YAKE, Wikipedia et APIs Google.