GitHub Data Explorer
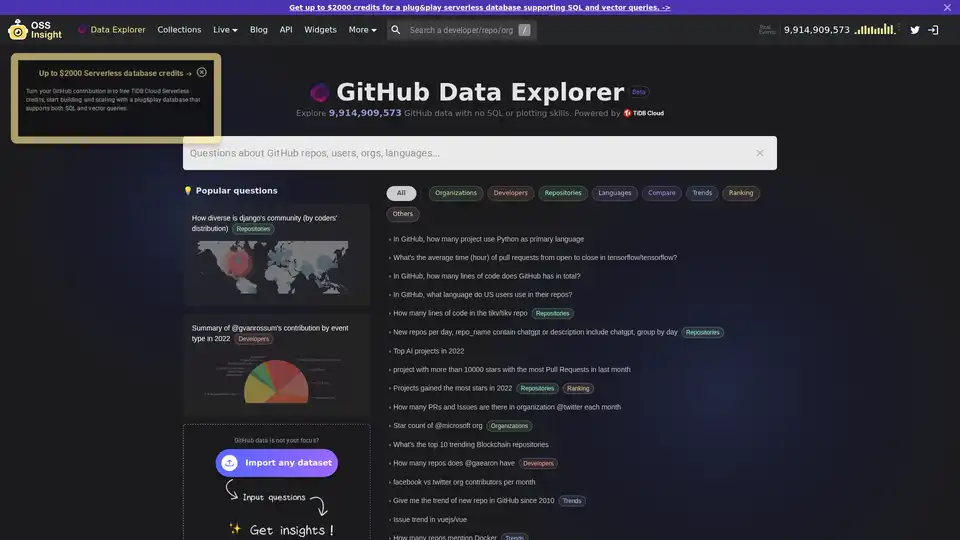
Vue d'ensemble de GitHub Data Explorer
Qu'est-ce que GitHub Data Explorer ?
GitHub Data Explorer est un outil puissant alimenté par l'IA conçu pour simplifier l'analyse des données d'événements GitHub. Hébergé sur OSS Insight, il permet aux utilisateurs de découvrir des insights précieux à partir de milliards d'événements GitHub sans nécessiter d'expertise SQL ni de compétences en tracé de graphiques. En exploitant le traitement du langage naturel, vous pouvez simplement décrire ce que vous recherchez, et l'outil génère la requête SQL appropriée, l'exécute sur un ensemble de données massif et fournit des résultats visuellement attractifs. Cela en fait une ressource inestimable pour les développeurs, les analystes de données et les passionnés de l'open source qui souhaitent suivre les tendances, les contributions et les activités des dépôts de manière effortless.
Que vous soyez curieux de la diversité des codeurs d'une communauté, des schémas de contribution de figures clés comme Guido van Rossum, ou de la croissance des projets IA sur GitHub, GitHub Data Explorer transforme l'exploration de données complexe en une conversation intuitive. Il est construit sur des sources de données fiables comme GH Archive, garantissant que vous travaillez avec des données publiques GitHub remontant à 2011, mises à jour en temps réel via la GitHub event API.
Comment fonctionne GitHub Data Explorer ?
Le flux de travail de GitHub Data Explorer est simple et convivial, propulsé par des technologies IA de pointe. Voici un aperçu étape par étape :
Saisissez votre question : Commencez par taper une requête en langage naturel dans la boîte de recherche. Par exemple, « Combien de nouveaux repos mentionnent ChatGPT par jour ? » ou « Quelle est la tendance des dépôts Rust sur les 10 dernières années ? » L'outil suggère des questions populaires pour inspirer vos recherches, couvrant des sujets comme les dépôts, les développeurs, les organisations, les langages, les tendances et les classements.
Traduction IA vers SQL : En coulisses, le moteur IA —construit sur l'API OpenAI's ChatGPT— interprète votre question et la traduit en code SQL précis. Cette capacité Text2SQL gère les nuances de la structure de données de GitHub, interrogeant un backend alimenté par TiDB Cloud, une base de données scalable et entièrement gérée qui supporte des volumes massifs (plus de 5 milliards d'événements) et des charges analytiques complexes.
Exécution de la requête et visualisation : Le SQL généré s'exécute sur la base de données TiDB Cloud, extrayant des données en temps réel ou historiques de GH Archive et de la GitHub API. Les résultats sont ensuite visualisés à l'aide d'Apache ECharts, présentant des graphiques, des tendances et des résumés faciles à interpréter. Aucune codification manuelle ou manipulation de données n'est requise.
Ce processus assure efficacité et précision, bien que l'IA soit une technologie en évolution. Pour de meilleurs résultats, utilisez une formulation claire et spécifique liée à la terminologie GitHub — comme des noms complets de dépôts (p. ex., « facebook/react ») ou des handles d'utilisateurs exacts (p. ex., « torvalds » au lieu de « Linus »).
Fonctionnalités et capacités clés
GitHub Data Explorer se distingue par son ensemble robuste de fonctionnalités adaptées à l'analyse OSS (open-source software) :
Catégories de requêtes diverses : Explorez les dépôts (p. ex., lignes de code dans des projets spécifiques comme tikv/tikv), les développeurs (p. ex., classements des contributeurs pour facebook/react), les organisations (p. ex., PRs et issues chez @twitter mensuelles), les langages (p. ex., langages de dépôts préférés des utilisateurs US), les tendances (p. ex., nouveaux dépôts depuis 2010), et plus encore.
Requêtes pré-construites populaires : Lancez votre analyse avec des exemples prêts à l'emploi, tels que « Top AI projects in 2022 » ou « Star count trends for @microsoft org. » Ces exemples mettent en lumière des insights à fort impact comme les classements de dépôts blockchain ou la montée de Python comme langage principal.
Intégration de datasets personnalisés : Au-delà de GitHub, vous pouvez importer n'importe quel dataset en utilisant la fonctionnalité intégrée Chat2Query dans TiDB Cloud, étendant son utilité à des besoins plus larges d'exploration de données.
Données en temps réel et historiques : Combine des mises à jour en streaming de la GitHub event API avec des données archivées depuis 2011, offrant une vue complète de l'évolution de l'OSS.
Sorties visuelles : Les résultats ne sont pas seulement des données brutes — ils sont transformés en graphiques interactifs, des diagrammes et des résumés pour une compréhension rapide.
Le backend de l'outil, TiDB Cloud, excelle dans la gestion de charges de travail à haut volume et mixtes, le rendant idéal pour scaler avec la croissance de l'écosystème GitHub.
Cas d'usage pratiques et applications
GitHub Data Explorer excelle dans divers scénarios où comprendre les dynamiques OSS est crucial :
Analyse de tendances pour les développeurs : Suivez la popularité des technologies, comme la croissance mensuelle des dépôts mentionnant Docker ou les tendances MoM (month-over-month) dans l'adoption de Rust. Cela aide les développeurs à identifier des outils et langages émergents.
Insights sur la communauté et les contributions : Analysez la diversité des contributeurs dans des projets comme Django ou comparez des organisations comme Facebook vs. Twitter en termes de contributeurs mensuels. C'est parfait pour évaluer la santé de la communauté.
Benchmarking de projets : Pour les propriétaires de dépôts, interrogez des métriques comme le temps moyen de résolution des pull requests (p. ex., dans tensorflow/tensorflow) ou le total d'étoiles gagnées en un an pour se benchmarker contre les pairs.
Recherche et reporting : Les académiciens ou analystes peuvent générer des données sur les surges de projets IA, tels que des dépôts avec plus de 10 000 étoiles et une haute activité PR, alimentant des rapports sur l'innovation OSS.
Marketing et intelligence d'affaires : Les organisations peuvent surveiller leur empreinte GitHub, comme le nombre de dépôts de @gaearon ou les tendances d'étoiles de @microsoft, pour informer leur stratégie.
En substance, c'est l'outil de prédilection pour quiconque a besoin de plongées rapides assistées par IA dans le vaste lac de données de GitHub sans le fardeau des outils analytiques traditionnels.
Pour qui est GitHub Data Explorer ?
Cet outil est conçu pour un large public, en particulier ceux sans compétences techniques approfondies en bases de données ou visualisation :
Utilisateurs non techniques : Marketeurs, gestionnaires de produits ou journalistes qui veulent des insights OSS mais manquent de compétences SQL.
Développeurs et analystes de données : Professionnels occupés cherchant un prototypage rapide de requêtes pour tendances, classements ou comparaisons.
Passionnés d'OSS et chercheurs : Contributeurs suivant l'élan des projets ou étudiant les patterns d'adoption de langages.
Équipes utilisant TiDB Cloud : S'intègre de manière fluide, attirant les utilisateurs déjà dans l'écosystème PingCAP.
Des limitations existent — l'IA peut galérer avec des requêtes hautement complexes ou ambiguës en raison de lacunes contextuelles ou de connaissances de domaine, et le dataset est limité aux événements publics GitHub. Des instabilités de service ou limites de taux (15 questions/heure) peuvent survenir, mais des optimisations comme l'utilisation de templates suggérés atténuent cela.
Pourquoi choisir GitHub Data Explorer ?
Dans un océan d'outils analytiques, GitHub Data Explorer se distingue par son focus spécialisé sur les données GitHub, sa simplicité IA et son backend de grade entreprise. Contrairement à l'écriture manuelle de SQL ou aux outils BI génériques, il démocratise l'accès à l'intelligence OSS, économisant des heures de configuration. Soutenu par des technologies comme React, TypeScript et Docusaurus, il est fiable et centré sur l'utilisateur.
Les utilisateurs apprécient la boucle de feedback : partagez des suggestions via Twitter (@OSSInsight) ou par email pour aider à l'améliorer. Pour des plongées plus profondes, consultez des ressources liées comme le blog « How OSS Insight Works » ou les tutoriels TiDB Cloud.
Si vous explorez le pouls de GitHub — des tendances d'issues dans vuejs/vue aux lignes de code totales sur la plateforme — GitHub Data Explorer est votre meilleur point de départ. Essayez-le aujourd'hui sur OSS Insight et transformez la curiosité naturelle en insights actionnables.
Gestion des Tâches et Projets par IA Résumé de Document et Lecture par IA Recherche Intelligente par IA Analyse de Données par IA Flux de Travail Automatisé
Meilleurs outils alternatifs à "GitHub Data Explorer"
Hex est l'espace d'analyse alimenté par l'IA conçu pour les équipes qui accélèrent les réponses, améliorent les décisions et explorent les données de manière collaborative avec des carnets, des applications et des outils d'auto-service.
NeoBase est un copilote IA pour base de données qui vous permet d'interroger, d'analyser et de gérer des bases de données en langage naturel. Prend en charge PostgreSQL, MySQL, MongoDB et plus encore. Open source et auto-hébergé.
CodeSquire est un assistant de rédaction de code IA pour les data scientists, les ingénieurs et les analystes. Générez des complétions de code et des fonctions complètes adaptées à votre cas d'utilisation de la science des données dans Jupyter, VS Code, PyCharm et Google Colab.
Rapidwork est une plateforme alimentée par l'IA avec des outils comme Datafetch pour les requêtes, PDFsense pour l'analyse de documents et Designbox pour la création de graphiques, aidant les utilisateurs à booster leur productivité dans les tâches de design et de recherche.