Avian API
Vue d'ensemble de Avian API
Avian API : L'inférence d'IA la plus rapide pour les LLM open source
Avian API est une plateforme qui fournit l'inférence d'IA la plus rapide pour les grands modèles de langage (LLM) open source comme Llama. Elle permet aux utilisateurs de déployer et d'exécuter des LLM depuis Hugging Face à des vitesses 3 à 10 fois plus rapides que les moyennes du secteur. Avec Avian, les utilisateurs peuvent bénéficier d'une inférence d'IA de qualité production sans limite de débit, en tirant parti de l'architecture sans serveur ou en déployant n'importe quel LLM depuis Hugging Face.
Qu'est-ce qu'Avian API ?
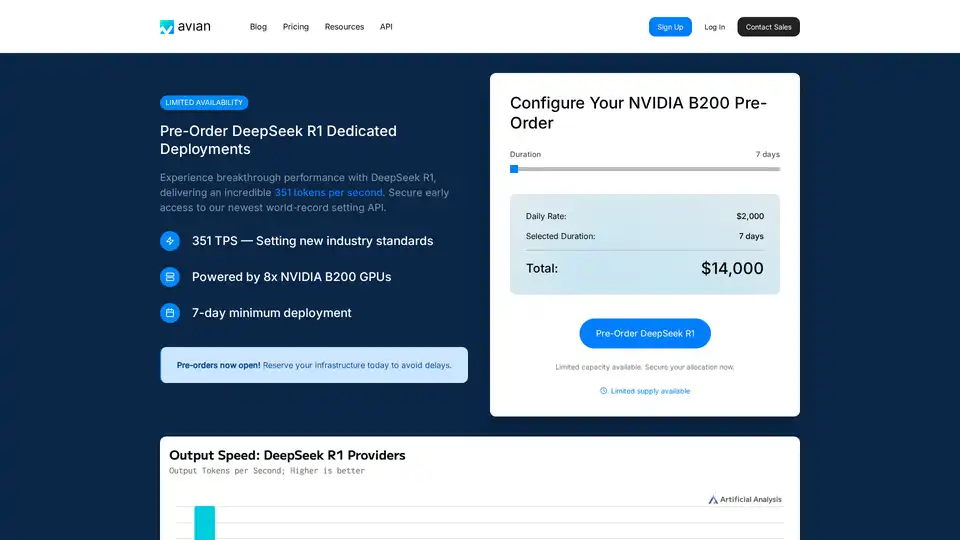
Avian API est conçue pour fournir une inférence d'IA haute performance, en mettant l'accent sur la vitesse, la confidentialité et la facilité d'utilisation. Elle se distingue en offrant des vitesses d'inférence de pointe, en particulier sur des modèles tels que DeepSeek R1, où elle atteint 351 tokens par seconde (TPS). Ces performances sont optimisées par l'architecture NVIDIA B200, établissant de nouvelles normes dans le paysage de l'inférence d'IA.
Comment fonctionne Avian API ?
Avian API fonctionne en tirant parti d'une infrastructure optimisée et de techniques propriétaires pour accélérer le processus d'inférence. Les principales fonctionnalités sont les suivantes :
- Inférence à grande vitesse: Atteint jusqu'à 351 TPS sur des modèles tels que DeepSeek R1.
- Intégration Hugging Face: Permet le déploiement de n'importe quel modèle Hugging Face avec une configuration minimale.
- Optimisation et mise à l'échelle automatiques: Optimise et met à l'échelle automatiquement les modèles pour garantir des performances constantes.
- Point de terminaison d'API compatible avec OpenAI: Fournit un point de terminaison d'API facile à utiliser compatible avec OpenAI, simplifiant l'intégration dans les flux de travail existants.
- Performances et confidentialité de niveau entreprise: Repose sur une infrastructure Microsoft Azure sécurisée et approuvée SOC/2 sans stockage de données.
Principales fonctionnalités et avantages
- Vitesses d'inférence les plus rapides: Avian API offre une vitesse d'inférence inégalée, ce qui la rend idéale pour les applications nécessitant des réponses en temps réel.
- Intégration facile: Grâce à son API compatible avec OpenAI, Avian peut être facilement intégrée aux projets existants avec un minimum de modifications de code.
- Rentable: En optimisant l'utilisation des ressources, Avian contribue à réduire les coûts associés à l'inférence d'IA.
- Confidentialité et sécurité: Avian garantit la confidentialité et la sécurité des données grâce à sa conformité SOC/2 et à ses options d'hébergement privé.
Comment utiliser Avian API
L'utilisation d'Avian API implique quelques étapes simples :
- S'inscrire: Créer un compte sur la plateforme Avian.io.
- Obtenir votre clé d'API: Obtenir votre clé d'API unique à partir du tableau de bord.
- Sélectionner un modèle: Choisir votre modèle open source préféré parmi Hugging Face ou utiliser DeepSeek R1 pour des performances optimales.
- Intégrer l'API: Utiliser l'extrait de code fourni pour intégrer l'API Avian dans votre application.
Voici un exemple d'extrait de code pour utiliser l'API Avian :
from openai import OpenAI
import os
client = OpenAI(
base_url="https://api.avian.io/v1",
api_key=os.environ.get("AVIAN_API_KEY")
)
response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[
{
"role": "user",
"content": "What is machine learning?"
}
],
stream=True
)
for chunk in response:
print(chunk.choices[0].delta.content, end="")
Cet extrait de code montre comment utiliser l'API Avian pour générer une réponse à partir du modèle DeepSeek-R1. Il suffit de modifier la base_url et d'utiliser votre clé d'API pour commencer.
Pourquoi choisir Avian API ?
Avian API se distingue par son accent sur la vitesse, la sécurité et la facilité d'utilisation. Par rapport aux autres solutions d'inférence, Avian offre :
- Des performances supérieures: Atteindre 351 TPS sur DeepSeek R1, ce qui est nettement plus rapide que les concurrents tels que Together, Fireworks et Amazon.
- Un déploiement simplifié: Intégration de code en une seule ligne pour n'importe quel modèle Hugging Face.
- Une sécurité de niveau entreprise: Conformité SOC/2 et mode de confidentialité pour les conversations.
À qui s'adresse Avian API ?
Avian API est idéale pour :
- Les entreprises: Les entreprises qui ont besoin d'une inférence d'IA haute performance, sécurisée et évolutive.
- Les développeurs: Les développeurs qui recherchent une API facile à utiliser pour intégrer l'IA dans leurs applications.
- Les chercheurs: Les chercheurs qui ont besoin d'une inférence rapide et fiable pour leurs modèles d'IA.
Conclusion
Avian API fournit l'inférence d'IA la plus rapide pour les LLM open source, ce qui en fait un outil essentiel pour tous ceux qui cherchent à exploiter la puissance de l'IA dans leurs projets. Grâce à ses performances à grande vitesse, à son intégration facile et à sa sécurité de niveau entreprise, Avian API établit de nouvelles normes dans le paysage de l'inférence d'IA. Que vous déployiez des modèles depuis Hugging Face ou que vous tiriez parti de l'architecture NVIDIA B200 optimisée, Avian API offre une vitesse et une efficacité inégalées.
Assistant de Programmation par IA Complétion Automatique de Code Révision et Optimisation du Code par IA Développement Low-Code et No-Code par IA
Meilleurs outils alternatifs à "Avian API"
Nexa SDK permet une inférence IA rapide et privée sur l'appareil pour les modèles LLM, multimodaux, ASR et TTS. Déployez sur les appareils mobiles, PC, automobiles et IoT avec des performances prêtes pour la production sur NPU, GPU et CPU.

Release.ai simplifie le déploiement de modèles d'IA avec une latence inférieure à 100 ms, une sécurité de niveau entreprise et une évolutivité transparente. Déployez des modèles d'IA prêts pour la production en quelques minutes et optimisez les performances grâce à une surveillance en temps réel.

Unsloth AI offre un fine-tuning open source et un apprentissage par renforcement pour les LLM comme gpt-oss et Llama, avec une formation 30 fois plus rapide et une utilisation réduite de la mémoire, ce qui rend la formation à l'IA accessible et efficace.
DeepSeek-v3 est un modèle d'IA basé sur l'architecture MoE, fournissant des solutions d'IA stables et rapides avec une formation étendue et une prise en charge multilingue.