UseScraper
Descripción general de UseScraper
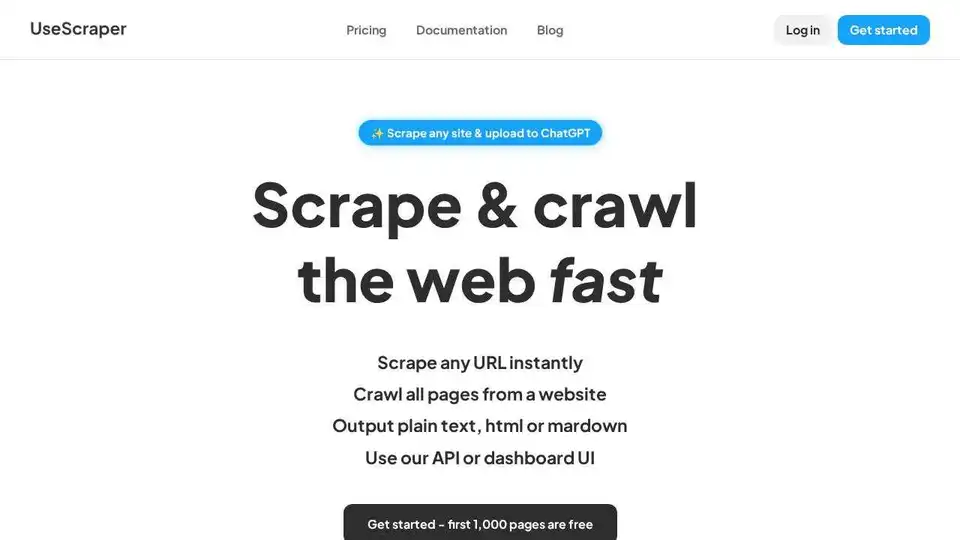
UseScraper: API Rápida para Web Scraping y Crawling
¿Qué es UseScraper? UseScraper es una API de web scraping y crawling potente y eficiente diseñada para extraer datos de sitios web de forma rápida y fiable. Permite a los usuarios hacer scraping de cualquier URL al instante, rastrear sitios web completos y generar datos en varios formatos adecuados para diversas aplicaciones.
¿Cómo funciona UseScraper? UseScraper utiliza una arquitectura robusta construida para la velocidad y la escalabilidad. Emplea un navegador Chrome real con renderización de JavaScript para manejar incluso las páginas web más complejas. El contenido se extrae y se guarda en formatos HTML, texto plano o Markdown.
Características Principales:
- Scraping Instantáneo: Haz scraping de cualquier URL en segundos.
- Crawling Completo: Rastrea todas las páginas de un sitio web.
- Salida Flexible: Genera datos en texto plano, HTML o Markdown.
- Renderización de JavaScript: Utiliza un navegador Chrome real para un scraping preciso.
- Proxies Automáticos: Evita la limitación de velocidad con proxies de rotación automática.
- Crawling Multi-Sitio: Incluye varios sitios web en una sola solicitud de trabajo de rastreo.
- Excluir Páginas: Excluye URLs específicas de un rastreo con patrones glob.
- Excluir Elementos del Sitio: Usa selectores CSS para excluir contenido repetitivo.
- Actualizaciones de Webhook: Recibe notificaciones sobre el estado y la finalización del trabajo de rastreo.
- Almacén de Datos de Salida: Los resultados del rastreador se almacenan y son accesibles a través de la API.
- Auto Caducidad de Datos: Establece una auto-caducidad en los datos guardados.
Casos de Uso:
- Extracción de Datos para Modelos de AI: Perfecto para proporcionar a los sistemas de AI datos limpios y estructurados en formato Markdown.
- Investigación de Mercado: Recopila datos sobre competidores, productos y tendencias del mercado.
- Agregación de Contenido: Recopila artículos, noticias y publicaciones de blog de diversas fuentes.
- Monitorización SEO: Realiza un seguimiento de las clasificaciones de los sitios web e identifica áreas de mejora.
- Generación de Leads: Extrae información de contacto de sitios web.
Precios:
UseScraper ofrece planes de precios flexibles para adaptarse a diferentes necesidades:
- Pago por uso: 0 $/mes + 1 $ por cada 1000 páginas web. Incluye las APIs de Scraper & Crawler, renderización de JavaScript y scraping & crawling paralelos súper rápidos.
- Pro: 99 $/mes + 1 $ por cada 1000 páginas web. Incluye todas las características gratuitas más proxies avanzados, trabajos concurrentes ilimitados, crawling de páginas ilimitado y soporte prioritario.
Nivel Gratuito:
- Comienza con una cuenta gratuita y tus primeras 1000 páginas son gratis.
Cómo usar UseScraper:
- Regístrate: Crea una cuenta gratuita en el sitio web de UseScraper.
- Introduce la URL: Introduce la URL que deseas scrapear o rastrear.
- Configura los Ajustes: Elige el formato de salida deseado (Markdown, texto plano o HTML) y cualquier regla de rastreo específica.
- Ejecuta el Trabajo: Inicia el trabajo de scraping o crawling.
- Accede a los Datos: Recupera los datos extraídos a través de la API o la interfaz de usuario del panel de control.
¿Por qué es importante UseScraper?
En el mundo actual impulsado por los datos, el acceso a información precisa y oportuna es crucial. UseScraper simplifica el proceso de web scraping y crawling, permitiendo a las empresas y a los individuos recopilar los datos que necesitan para tomar decisiones informadas.
¿Cuál es la mejor manera de extraer datos de sitios web?
UseScraper ofrece una interfaz fácil de usar y una API potente, lo que la convierte en la mejor manera de extraer datos de sitios web, independientemente de su complejidad. Los proxies automáticos, la renderización de JavaScript y los diversos formatos de salida garantizan una experiencia de extracción de datos fluida y eficiente.
Gestión de Tareas y Proyectos con IA Resumido y Lectura de Documentos con IA Búsqueda Inteligente con IA Análisis de Datos con IA Flujo de Trabajo Automatizado
Mejores herramientas alternativas a "UseScraper"
WebCrawler API simplifica la extracción de datos de sitios web para el entrenamiento de IA. Rastrea y extrae contenido en varios formatos con facilidad. Maneja proxies, reintentos y navegadores sin cabeza.
Octoparse es una herramienta de web scraping sin código que convierte las páginas web en datos estructurados con clics. Cuenta con asistencia de IA, solución en la nube 24/7, plantillas preestablecidas y opciones de configuración flexibles.
Apify es una plataforma en la nube completa para web scraping, automatización de navegadores y agentes de IA. Utilice herramientas preconstruidas o cree sus propios Actors para la extracción de datos y la automatización del flujo de trabajo.
BrowserAct es un web scraper y herramienta de automatización impulsada por IA que te permite extraer datos de cualquier sitio sin necesidad de programar. Automatiza flujos de trabajo e intégrate con herramientas como n8n y Make.