ChatTTS
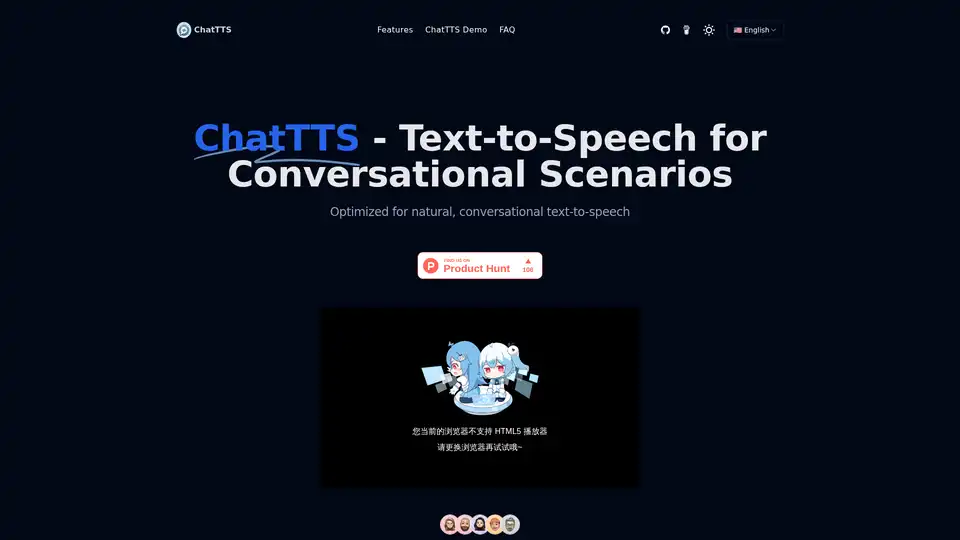
Overview of ChatTTS
What is ChatTTS?
ChatTTS is an advanced open-source text-to-speech (TTS) model specifically designed for conversational applications. Unlike generic TTS systems, ChatTTS is optimized for dialogue scenarios, making it particularly effective for integration with large language model (LLM) assistants, conversational audio applications, and video introductions. Developed by 2noise and hosted on GitHub, this model supports both Chinese and English languages, delivering high-quality and natural-sounding speech synthesis.
How Does ChatTTS Work?
ChatTTS leverages deep learning techniques trained on approximately 100,000 hours of Chinese and English speech data. This extensive training enables the model to capture nuanced speech patterns, intonations, and emotional tones essential for conversational contexts. The architecture includes a decoder that processes text inputs and generates corresponding audio waveforms, ensuring fluid and context-aware voice output.
Key Technical Features
- Multi-language Support: Seamlessly handles both English and Chinese text inputs.
- Large-scale Training: Utilizes 100,000 hours of curated speech data for robust performance.
- Real-time Processing: Efficient inference capabilities suitable for live applications.
- Customization Options: Supports fine-tuning with user-specific datasets for unique voice profiles.
Core Functions and Applications
ChatTTS excels in several practical applications:
1. LLM Assistant Dialogue
Ideal for enhancing AI chatbots and virtual assistants with natural voice responses, improving user engagement in customer service, education, and entertainment platforms.
2. Conversational Audio Content
Generates voiceovers for podcasts, audiobooks, and video narrations where a conversational tone is preferred over robotic speech.
3. Multimedia Introductions
Creates engaging audio and video introductions for apps, websites, or presentations, adding a professional touch with human-like narration.
4. Educational Tools
Supports e-learning platforms by converting textual educational content into spoken language, aiding accessibility and comprehension.
How to Use ChatTTS?
Integrating ChatTTS into your projects is straightforward:
Installation: Clone the repository from GitHub (
https://github.com/2noise/ChatTTS) and install dependencies using pip:pip install torch ChatTTSBasic Implementation: Use the provided Python API to initialize the model, load pre-trained weights, and synthesize speech:
import torch import ChatTTS from IPython.display import Audio chat = ChatTTS.Chat() chat.load_models() texts = ["Your input text here"] wavs = chat.infer(texts, use_decoder=True) Audio(wavs[0], rate=24000, autoplay=True)Advanced Customization: Developers can fine-tune the model using custom datasets or integrate it via APIs into web, mobile, or desktop applications.
Why Choose ChatTTS?
- Optimized for Conversation: Outperforms generic TTS models in dialogue-heavy scenarios.
- High-Quality Output: Produces natural and expressive speech thanks to extensive training data.
- Open-Source Flexibility: The planned release of a base model trained on 40,000 hours of data will foster community innovation.
- Multilingual Capabilities: Effortlessly switches between English and Chinese, catering to global users.
- Developer-Friendly: Comprehensive documentation and easy integration with popular programming environments.
Who is ChatTTS For?
- AI Developers: Building conversational AI agents, chatbots, or voice-enabled apps.
- Content Creators: Needing voiceovers for videos, podcasts, or educational materials.
- Researchers: Exploring speech synthesis technologies or adapting TTS for academic projects.
- Businesses: Enhancing customer interactions with natural voice responses in support systems.
Future Developments
The ChatTTS team is actively working on:
- Enhancing model controllability and adding watermarking features for security.
- Expanding language support beyond Chinese and English.
- Releasing the open-source base model to encourage community contributions.
Limitations and Considerations
While powerful, ChatTTS has some constraints:
- Performance may vary with complex or lengthy texts.
- Real-time synthesis requires adequate computational resources.
- Currently focused on Chinese and English, though expansion is planned.
For support or contributions, users can engage via GitHub issues or community forums, providing feedback to drive continuous improvement.
AI Voice Synthesis AI Voice Changer AI Music Creation Speech to Text AI Voice Customer Service and Assistant Podcast and Video Dubbing
Best Alternative Tools to "ChatTTS"
Fotol AI provides a gateway to AGI, offering powerful AI solutions for video, image, speech, music, 3D asset generation, and conversation. Dream it, make it!
LMNT delivers fast, lifelike, affordable AI speech. Enjoy studio-quality voice clones and low latency streaming ideal for conversational apps, games, and agents. Engineered for reliability, scale effortlessly with technology built by an ex-Google team.
PodGen.io is an AI podcast generator that converts text, YouTube videos, PDFs, blogs, and more into professional podcasts. Features 1000+ voices, 25+ languages, editing tools, analytics, and easy distribution. Ideal for creators, educators, and marketers.

Discover Skelet AI, your all-in-one platform for generating AI-powered content, stunning images, and natural text-to-speech in 80+ languages. Free plan available with premium upgrades for HD features.