xMem
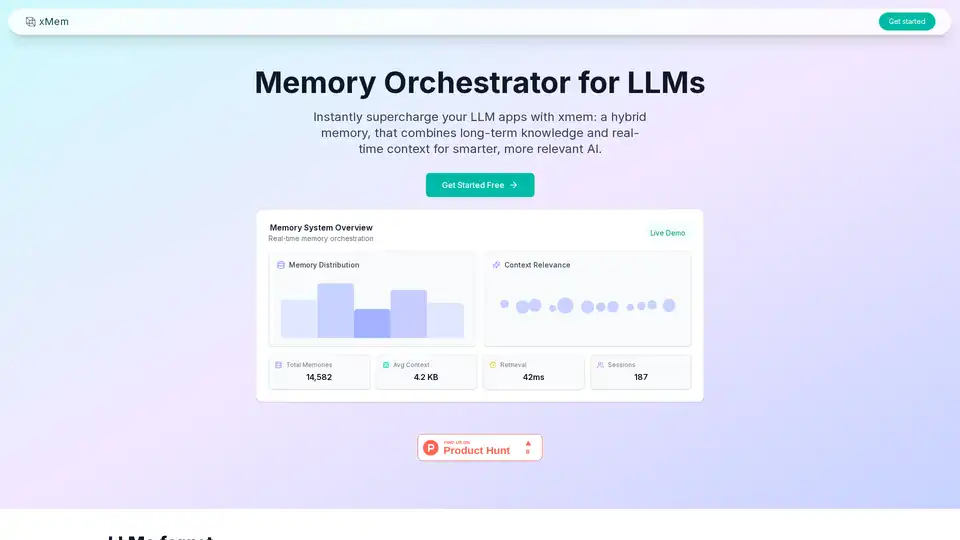
Übersicht von xMem
Was ist xMem?
xMem ist ein Speicher-Orchestrator für LLMs (Large Language Models), der langfristiges Wissen und Echtzeitkontext kombiniert, um intelligentere und relevantere KI-Anwendungen zu erstellen.
Wie verwende ich xMem?
Integrieren Sie xMem mithilfe der API oder des Dashboards in Ihre LLM-Anwendung. xMem stellt automatisch den besten Kontext für jeden LLM-Aufruf zusammen, sodass keine manuelle Abstimmung erforderlich ist.
const orchestrator = new xmem({
vectorStore: chromadb,
sessionStore: in-memory,
llmProvider: mistral
});
const response = await orchestrator.query({
input: "Tell me about our previous discussion"
});
Warum ist xMem wichtig?
LLMs vergessen oft Informationen zwischen Sitzungen, was zu einer schlechten Benutzererfahrung führt. xMem behebt dies, indem es jedem Benutzer einen persistenten Speicher zur Verfügung stellt, um sicherzustellen, dass die KI immer relevant, genau und auf dem neuesten Stand ist.
Hauptmerkmale:
- Langzeitgedächtnis: Speichern und Abrufen von Wissen, Notizen und Dokumenten mit Vektorsuche.
- Sitzungsspeicher: Verfolgen Sie aktuelle Chats, Anweisungen und Kontexte für Aktualität und Personalisierung.
- RAG-Orchestrierung: Stellen Sie automatisch den besten Kontext für jeden LLM-Aufruf zusammen. Keine manuelle Abstimmung erforderlich.
- Wissensgraph: Visualisieren Sie Verbindungen zwischen Konzepten, Fakten und Benutzerkontext in Echtzeit.
Vorteile:
- Verlieren Sie niemals Wissen oder Kontext zwischen Sitzungen.
- Steigern Sie die LLM-Genauigkeit mit orchestriertem Kontext.
- Funktioniert mit jedem Open-Source-LLM und jeder Vektor-DB.
- Einfache API und Dashboard für nahtlose Integration und Überwachung.
KI-Aufgaben- und Projektmanagement KI-Dokumentenzusammenfassung und -Lesen KI-Smart-Suche KI-Datenanalyse Automatisierter Arbeitsablauf
Beste Alternativwerkzeuge zu "xMem"
Supermemory ist eine schnelle Speicher-API und ein Router, der Ihren LLM-Apps Langzeitgedächtnis hinzufügt. Speichern, rufen und personalisieren Sie in Millisekunden mit dem Supermemory SDK und MCP.
vLLM ist eine Inferenz- und Serving-Engine mit hohem Durchsatz und Speichereffizienz für LLMs, die PagedAttention und kontinuierliche Batchverarbeitung für optimierte Leistung bietet.
Agents-Flex ist ein einfaches und leichtgewichtiges LLM-Anwendungsentwicklungs-Framework, das in Java entwickelt wurde und LangChain ähnelt.
GPT4All ermöglicht die private, lokale Ausführung großer Sprachmodelle (LLMs) auf alltäglichen Desktops ohne API-Aufrufe oder GPUs. Zugängliche und effiziente LLM-Nutzung mit erweiterter Funktionalität.