Friendli Inference
Übersicht von Friendli Inference
Friendli Inference: Die schnellste LLM-Inferenz-Engine
Was ist Friendli Inference?
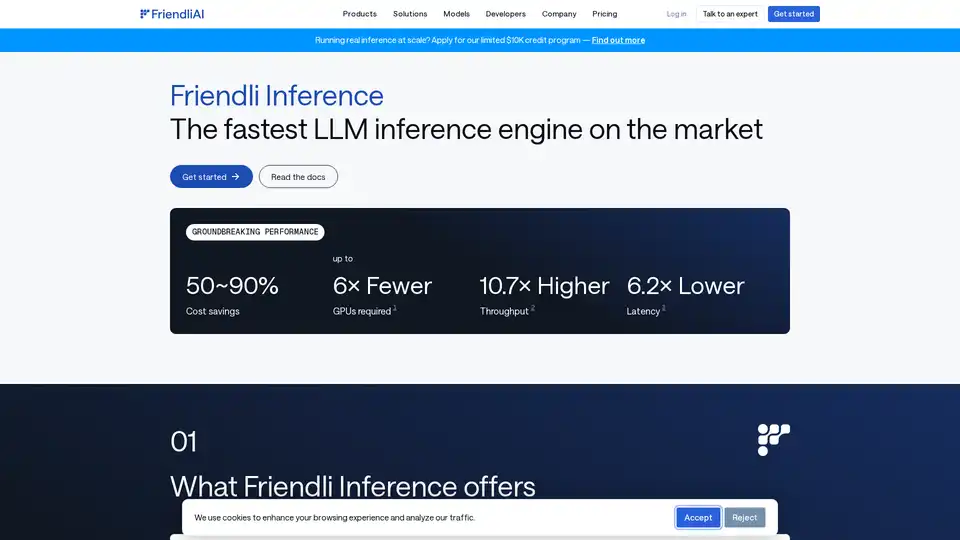
Friendli Inference ist eine hochoptimierte Engine, die entwickelt wurde, um das Serving von Large Language Models (LLMs) zu beschleunigen und die Kosten erheblich um 50-90% zu senken. Sie zeichnet sich als die schnellste LLM-Inferenz-Engine auf dem Markt aus und übertrifft vLLM und TensorRT-LLM in Leistungstests.
Wie funktioniert Friendli Inference?
Friendli Inference erzielt seine bemerkenswerte Leistung durch mehrere Schlüsseltechnologien:
- Iteration Batching: Diese innovative Batching-Technologie verarbeitet effizient gleichzeitige Generierungsanforderungen und erzielt einen bis zu zehnmal höheren LLM-Inferenzdurchsatz im Vergleich zum herkömmlichen Batching, während die gleichen Latenzanforderungen eingehalten werden. Sie ist durch Patente in den USA, Korea und China geschützt.
- DNN Library: Friendli DNN Library umfasst eine Reihe optimierter GPU-Kernel, die speziell für generative AI entwickelt wurden. Diese Bibliothek ermöglicht eine schnellere LLM-Inferenz für verschiedene Tensorformen und Datentypen, unterstützt Quantisierung, Mixture of Experts (MoE) und LoRA-Adapter.
- Friendli TCache: Dieses intelligente Caching-System identifiziert und speichert häufig verwendete Berechnungsergebnisse und reduziert die Arbeitslast auf GPUs, indem es die zwischengespeicherten Ergebnisse nutzt.
- Speculative Decoding: Friendli Inference unterstützt nativ spekulative Dekodierung, eine Optimierungstechnik, die die LLM/LMM-Inferenz beschleunigt, indem sie fundierte Vermutungen über zukünftige Token parallel anstellt, während das aktuelle Token generiert wird. Dies gewährleistet identische Modellausgaben bei einem Bruchteil der Inferenzzeit.
Hauptmerkmale und Vorteile
- Erhebliche Kosteneinsparungen: Reduzieren Sie die LLM-Serving-Kosten um 50-90%.
- Multi-LoRA Serving: Unterstützt gleichzeitig mehrere LoRA-Modelle auf weniger GPUs, sogar auf einer einzigen GPU.
- Breite Modellunterstützung: Unterstützt eine breite Palette von generativen AI-Modellen, einschließlich quantisierter Modelle und MoE.
- Bahnbrechende Leistung:
- Bis zu 6x weniger GPUs erforderlich.
- Bis zu 10,7x höherer Durchsatz.
- Bis zu 6,2x niedrigere Latenz.
Highlights
- Quantisiertes Mixtral 8x7B auf einer einzigen GPU ausführen: Friendli Inference kann ein quantisiertes Mixtral-7x8B-instruct v0.1 Modell auf einer einzelnen NVIDIA A100 80GB GPU ausführen und dabei mindestens 4,1x schnellere Reaktionszeiten und 3,8x ~ 23,8x höheren Token-Durchsatz im Vergleich zu einem Baseline vLLM-System erzielen.
- Quantisiertes Llama 2 70B auf einer einzigen GPU: Führen Sie AWQ-ed LLMs, wie z. B. Llama 2 70B 4-bit, nahtlos auf einer einzelnen A100 80 GB GPU aus, wodurch eine effiziente LLM-Bereitstellung und bemerkenswerte Effizienzsteigerungen ohne Genauigkeitseinbußen ermöglicht werden.
- Noch schnelleres TTFT mit Friendli TCache: Friendli TCache optimiert die Time to First Token (TTFT) durch die Wiederverwendung wiederkehrender Berechnungen und liefert 11,3x bis 23x schnellere TTFT im Vergleich zu vLLM.
Wie man Friendli Inference verwendet
Friendli Inference bietet drei Möglichkeiten, generative AI-Modelle auszuführen:
- Friendli Dedicated Endpoints: Erstellen und betreiben Sie generative AI-Modelle auf Autopilot.
- Friendli Container: Stellen Sie LLM- und LMM-Inferenz mit Friendli Inference in Ihrer privaten Umgebung bereit.
- Friendli Serverless Endpoints: Rufen Sie die schnelle und erschwingliche API für Open-Source generative AI-Modelle auf.
Warum Friendli Inference wählen?
Friendli Inference ist die ideale Lösung für Organisationen, die die Leistung und Kosteneffizienz ihrer LLM-Inferenz-Workloads optimieren möchten. Seine innovativen Technologien und seine breite Palette an Funktionen machen es zu einem leistungsstarken Werkzeug für die Bereitstellung und Skalierung von generativen AI-Modellen.
Für wen ist Friendli Inference geeignet?
Friendli Inference ist geeignet für:
- Unternehmen, die große Sprachmodelle einsetzen.
- Forscher, die mit generativer AI arbeiten.
- Entwickler, die AI-gestützte Anwendungen erstellen.
Bester Weg, um LLM-Inferenz zu optimieren?
Der beste Weg, um LLM-Inferenz zu optimieren, ist die Verwendung von Friendli Inference, das im Vergleich zu anderen Lösungen erhebliche Kosteneinsparungen, einen hohen Durchsatz und eine geringe Latenz bietet.
KI-Programmierassistent Automatische Codevervollständigung KI-Code-Überprüfung und -Optimierung KI-gesteuerte Low-Code- und No-Code-Entwicklung
Beste Alternativwerkzeuge zu "Friendli Inference"
vLLM ist eine Inferenz- und Serving-Engine mit hohem Durchsatz und Speichereffizienz für LLMs, die PagedAttention und kontinuierliche Batchverarbeitung für optimierte Leistung bietet.
Anyscale, powered by Ray, ist eine Plattform zum Ausführen und Skalieren aller ML- und KI-Workloads in jeder Cloud oder On-Premises-Umgebung. Erstellen, debuggen und implementieren Sie KI-Anwendungen einfach und effizient.
Predibase ist eine Entwicklerplattform zum Feinabstimmen und Bereitstellen von Open-Source-LLMs. Erzielen Sie unübertroffene Genauigkeit und Geschwindigkeit mit einer End-to-End-Trainings- und Bereitstellungsinfrastruktur mit Verstärkungsfeinabstimmung.
Float16.Cloud bietet serverlose GPUs für eine schnelle KI-Entwicklung. Führen Sie KI-Modelle ohne Einrichtung sofort aus, trainieren und skalieren Sie sie. Mit H100-GPUs, sekundengenauer Abrechnung und Python-Ausführung.